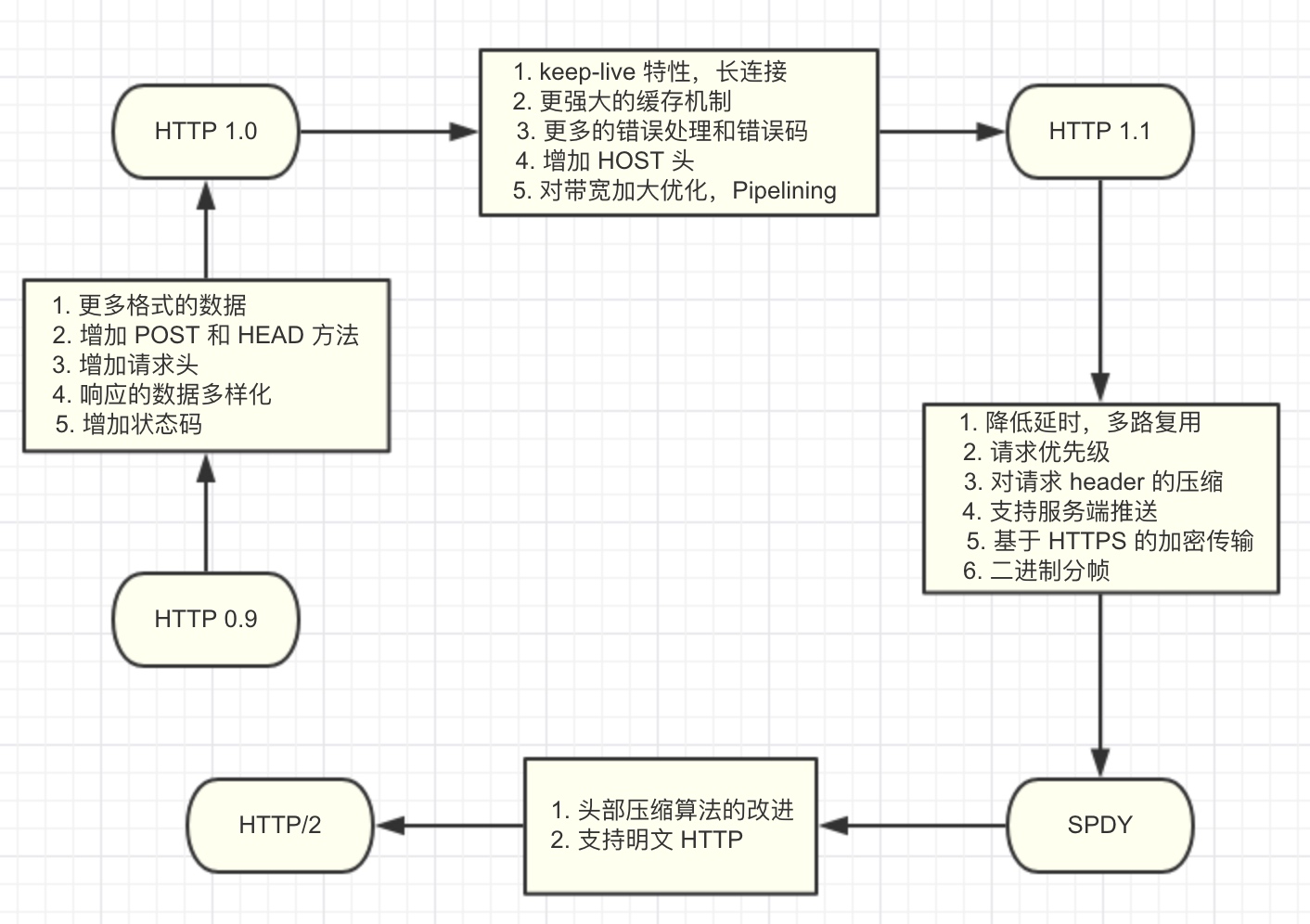
简介
这篇文章的主要包含如下内容:
- 可变对象和不可变对象
- NSString 的 copy 和 mutableCopy
- NSMutableString 的 copy 和 mutableCopy
- property 中 copy、strong 修饰 NSString
- property 中 copy、strong 修饰 NSMutableString
很多 iOS 开发的朋友会争论一个问题,我用 copy 和 strong 来修饰 NSString 对象都是一样的效果,在大部分情况下,这二者确实是没有区别,但是在特殊情况下,二者截然不同,所以我们必须搞清楚里面的道道。
我已经尽力简化了这篇文章的内容了,但依然需要你花个15分钟左右的时间,所以当你心情不错又没有其他事情的情况下,就可以来阅读了。
可变对象和不可变对象
在 Objective-C 中最常用来处理字符串的是 NSString 与 NSMutableString 这两个类,NSString 被创建赋值后字符串的内容与长度不能再做动态的修改,除非重新给这个字符串赋值。而 NSMutableString 被创建赋值后可以动态的修改字符串的内容。
那么简单来说,可变对象是指,对象的内容是可变的,例如 NSMutableString 对象。不可变的对象则相反,表示其内容不可变,例如 NSString 对象。
可变与不可变是针对对象来说的。在实际开发中,要根据实际的业务场景来选择使用可变还是不可变对象。今天我们只讨论 Objective-C 中 NSString 与 NSMutableString 这两个类,关于其他集合类的可变与不可变特性,后面专门再来写文章分享。
NSString 的 copy 和 mutableCopy
在 NSString.h 中,我们可以看到其定义如下:
1 | @interface NSString : NSObject <NSCopying, NSMutableCopying, NSSecureCoding> |
NSString.h 本身实现了 NSCopying, NSMutableCopying 这两个协议,协议的定义如下内容所示:
1 | @protocol NSCopying |
也就是说,我们可以针对 NSString 对象进行 copy 和 mutableCopy 的操作,妥妥的。
举一个简单的栗子,示例代码如下:
1 | NSString *name = @"www."; |
输出结果,如下:
1 | name addr: 0x10090ecf8, name content: www. |
从输出结果可以看出,三个对象的内容和地址都是一样的,经过 name 对象 copy 后的 name2 与 name 还是指向同一块内存地址。
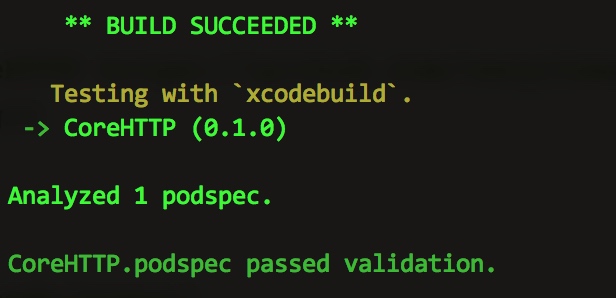
在断点过程中,发现无论是 name 还是 name1、name2 对象,其都是 ConstantString,表明三者都是不可变对象,如下图所示:
从这张图也说明了一个问题,NSString 对象经过 copy 后仍然是不可变对象。
紧接着,我们再来看看 mutableCopy 的使用情况,例子如下:
1 | NSString *name = @"www."; |
对象 name3 是经过 name 对象 mutableCopy 后的,这个时候因为我不确定 name3 到底是可变的还是不可变的,所以采用了 id 来修饰 name3 对象。
可以看一下输出内容:
1 | name addr: 0x104a6acf8, name content: www. |
可以看出,name3 的地址变了,再看一下断点的截图: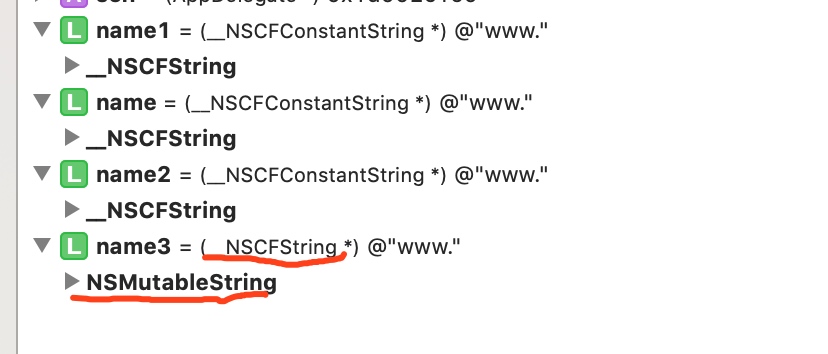
充分说明了 name3 经过不可变的 name 进行mutableCopy 后变成了可变对象。那么可以将上面的示例代码稍作修改:
1 | NSMutableString *name3 = [name mutableCopy]; |
从下面的输出结果也充分说明了 name3 经过不可变的 name 进行 mutableCopy 后变成了可变对象。输出结果如下:
1 | name3 addr: 0x1d0058270, name3 content: www.veryitman.com |
结论 1:
- 不可变的
NSString对象经过copy后,还是不可变对象。 - 不可变的
NSString对象经过mutableCopy后,变成了可变的NSMutableString对象。
NSMutableString 的 copy 和 mutableCopy
类 NSMutableString 继承自 NSString 的,其当然也是实现了 NSCopying, NSMutableCopying 这两个协议的。
1 | @interface NSMutableString : NSString |
我们还是看例子,示例代码如下:
1 | NSMutableString *name = [NSMutableString stringWithString:@"www."]; |
因为事先我们不知道 NSMutableString 经过 copy 和 mutableCopy 之后到底会变成可变还是不可变,上面的例子暂时将 name2 和 name3 用 id 来表示。
断点截图如下:
结合一下输出的日志:
1 | name addr: 0x1d044a980, name content: www. |
可以看出 name2 是一个不可变的 NSString 对象, name、name1 和 name3 都是可变的 NSMutableString 对象。
也可以从另外一个角度来验证一下上面的说法,我们修改一下代码:
1 | NSMutableString *name2 = [name copy]; |
运行后,可以看到,代码 [name2 appendString:@"veryitman.com"] 这里会引起 Crash,报错内容如下:
1 | -[NSTaggedPointerString appendString:]: unrecognized selector sent to instance 0xa0000002e7777774 |
也充分说明了,name2 是一个不可变的 NSString 对象。
结论 2:
- 可变的
NSMutableString对象经过copy后,会变成不可变的NSString对象。 - 可变的
NSMutableString对象经过mutableCopy后,仍然是可变的NSMutableString对象。
copy、strong 修饰 NSString
创建 Employee 文件,如下:
1 | @interface Employee : NSObject |
其 userName 属性是 copy。
使用示例,如下:
1 | Employee *employee = [Employee new]; |
在上面的示例中,故意将 NSMutableString 对象 newUserName 赋值给不可变的 NSString 对象 employee.userName,看一下输出结果,如下:
1 | --before-- employee.userName addr: 0x100096cf8, employee.userName content: John |
按照
1 | 可变的 `NSMutableString` 对象经过 `copy` 后,会变成不可变的 `NSString` 对象。 |
这个结论来看,employee.userName 肯定是不可变的对象,即使改变 newUserName 的内容也不会影响 employee.userName 这个对象的内容。
那么,我们将 employee.userName 的属性修饰符 copy 改为 strong,又会是什么样子呢?
我们修改两处代码
Employee.h
1 | @interface Employee : NSObject |
示例代码,只是打开之前会 crash 的部分
1 | // employee.userName 经过 strong 修饰过后, 彻底变成了可变对象 |
看一下输出日志:
1 | --before-- employee.userName addr: 0x1000a6cf8, employee.userName content: John |
可以看到 employee.userName 最终和 newUserName 的地址、内容完全相同了,彻底变成了可变对象。
另外,如果不是将可变的 NSMutableString 对象赋值给不可变的 NSString 对象,换句话说,NSString 对 NSString 赋值,那么使用 strong 和 copy 效果都是一样的。
示例代码(无论 employee.userName 使用 strong 还是 copy,效果都是 employee.userName 不可变的):
1 | Employee *employee = [Employee new]; |
copy、strong 修饰 NSMutableString
在 property 的修饰语中,只有 copy 修饰语而没有 mutableCopy 的修饰语。
Employee.h
1 | @interface Employee : NSObject |
示例代码:
1 | Employee *employee = [Employee new]; |
可以看出 copy 后的的可变对象还是不可变的。
那么,我们将 employee.userName 的属性修饰符 copy 改为 strong,又会是什么样子呢?
Employee.h
1 | @interface Employee : NSObject |
示例代码:
1 | Employee *employee = [Employee new]; |
经过 strong 修饰后,可变的 NSMutableString 对象还是可变的对象。
在这个部分的开始,说过在 property 中没有 mutableCopy 的修饰语,那么我们能否达到 mutableCopy 的效果呢?
很显然是可以的,我们可以重写属性的 set 方法,改造一下 Employee 的代码,如下:
Employee.h
1 | @interface Employee : NSObject |
Employee.m
1 | #import "Employee.h" |
这样,就达到了和是 strong 修饰语一样的效果了。
大家,可以使用同样的方法来实践一下 NSArray、NSMutableArry 等集合数据的 copy 以及 mutableCopy 的效果了。
小结
不可变的
NSString对象经过copy后,还是不可变对象。不可变的
NSString对象经过mutableCopy后,变成了可变的NSMutableString对象。可变的
NSMutableString对象经过copy后,会变成不可变的NSString对象。可变的
NSMutableString对象经过mutableCopy后,仍然是可变的NSMutableString对象。不可变的
NSString对象在 property 中,尽量使用copy来修饰,因为使用strong修饰符可变字符串如果给不可变字符串赋值后,会导致你原本预期发生了变化,除非你有特殊的目的才使用strong修饰符。可变的
NSMutableString对象在 property 中,尽量使用strong来修饰,除非你有特殊的目的才使用copy修饰符。虽然在 property 中没有
mutableCopy修饰符,但是可以通过重写其set方法来达到目的。
扫码关注,你我就各多一个朋友~